Если не нужны проблемы с индексацией, необходимо создать правильный файл robots.txt. Служебные и личные разделы проекта необходимо ограничить от индексирования. Сегодня поговорим о том, что такое файл robots.txt и как с ним работать. Если на сайте нет данного файла — робот посчитает всю информацию на сайте доступной к индексу.
Robots.txt — текстовый файл, содержащий правила индексирования сайта, которые написаны для роботов поисковых систем и указывающий на то, какие разделы ресурса разрешены для индексирования, а какие нет. Как создать robots.txt? Просто:
- Необходимо создать файл с названием «robots» и расширением txt в любом текстовом редакторе и прописать в нем соответствующие правила, о которых речь пойдет ниже
- Загрузите файл в корень сайта
Подойдет любой текстовый редактор, например, блокнот для OS Windows или Coda для Mac OS. Написали, сохранили и загрузили в корень сайта.
ПРАВИЛА И ДИРЕКТИВЫ
Директивы позволяют создать файл robots.txt для всех поисковиков, учитывая особенности каждого. В данном материале приведены лишь основные пункты, которые Вам понадобятся при настройке.
Директива User-agent определяет какому роботу будет адресовано сообщение. Если вы хотите прописать одинаковые правила для всех роботов, то необходимо в ней прописать символ «звездочки»:

Таким образом, мы запретили всем роботам поисковых систем просматривать раздел /secret. С помощью данной директивы Вы можете отдельно прописывать правила для роботов Yandex и Google. Таблица названий ботов большинства ПС:
- yandex.ru — бот Yandex
- google.com — бот Googlebot
- rambler.ru — бот StackRambler
- mail.ru — бот Mail.Ru
Директивы Disallow и Allow
Disallow — как вы уже поняли, запрещает роботу включать в индекс страницу, а Allow — разрешает.

Запретили скачивать любую информацию, кроме страницы /open.html.
Директива Host
Чтобы избежать проблемы с дублями сайта (или зеркалами) в Яндексе, необходимо прописать директиву host, в которой указывается основной домен сайта:

Таким образом, мы указали для бота Яндекс, что главное зеркало у сайта домен без www. В поиске Яндекса должно участвовать только главное зеркало сайта.
Обновлено: Яндекс перестал учитывать директорию host. Теперь заполнять ее необязательно.
Директива sitemap
Для ускорения индексации сайта рекомендуется использовать директиву sitemap, в которой указать карту сайта (файл sitemap.xml). Хотя более эффективным будет провести перелинковку страниц сайта между собой.

Как вы заметили, в примере указано три карты сайта. Достаточно и одной, если вы уместите информацию о новых страницах в файл размером до 500 кб. Ваша CMS может автоматически формировать файл большего размера. Необходимо следить за этим, так как «тяжелые» файлы могут привести к ошибке при индексировании.
Директива Crawl-delay позволяет задать боту минимальный период времени между окончанием изучения одной страницы и началом другой. Период времени указывается в секундах.

В примере мы задали таймаут в 15 секунд. Это значительно облегчит сервер.
ПРОВЕРКА ФАЙЛА РОБОТС НА ПРАВИЛЬНОСТЬ
Каждый может допустить ошибку при создании файла. Для избежания проблем, рекомендую проанализировать файл в Яндексе, перейдя на страницу в разделе Яндекс.Вебмастер — webmaster.yandex.ru/robots.xml. Необходимо указать имя сайта, загрузить файл robots.txt с сайта, либо указать правила в соответствующем окне. А дальше нажать на кнопку «проверить».
Аналогичный инструмент Вы можете найти в Google.
ПРИМЕР ФАЙЛА ROBOTS.TXT ДЛЯ WORDPRESS
Данный файл вы можете дополнять и менять по желанию:
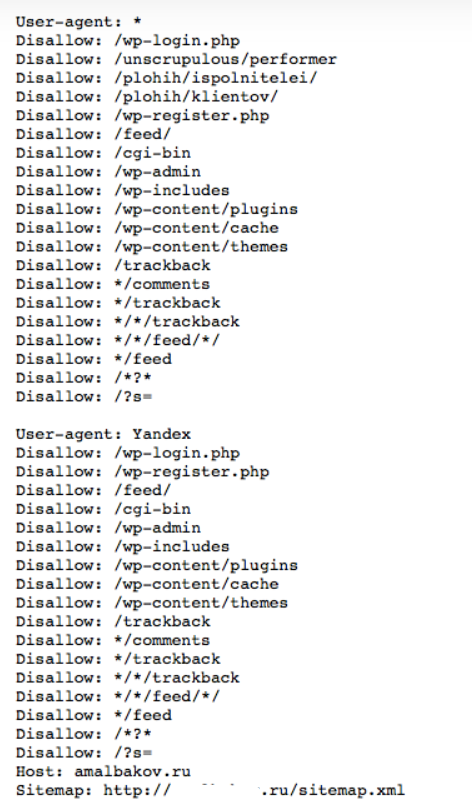
Комментарии в файле
В данном файле можно оставлять комментарии. Для этого используется решетка («#»). Будьте внимательны, так как можете случайно закрыть нужные разделы от индексирования. Например, не закрывайте якорные ссылки.
[…] якорные ссылки в файле robots.txt не нужно. До 2009 года проблема с ними была актуальна (в […]
[…] систем, — это неправильные инструкции файла robots.txt. Как ни странно, это происходит либо по незнанию самих […]